In Part I we discussed some conceptual proofs of the Sylow theorems. Two of those proofs involve reducing the existence of Sylow subgroups to the existence of Sylow subgroups of 
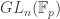

Posted in math, math.GR | Tagged finite fields, fixed point theorems, group actions | 1 Comment »
As an undergraduate the proofs I saw of the Sylow theorems seemed very complicated and I was totally unable to remember them. The goal of this post is to explain proofs of the Sylow theorems which I am actually able to remember, several of which use our old friend
The 

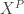
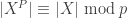
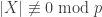
There will be some occasional historical notes taken from Waterhouse’s The Early Proofs of Sylow’s Theorem.
Posted in math, math.GT | Tagged fixed point theorems, group actions | 8 Comments »
This is a post I wanted to write some time ago; I’ve forgotten why, but it was short and cute enough to finish. Our starting point is the following observation:
Theorem 1: Universal lossless compression is impossible. That is, there is no function which takes as input finite strings (over some fixed alphabet) and always produces as output shorter finite strings (over the same alphabet) in such a way that the latter is recoverable from the former.
Posted in math, math.IT | 7 Comments »
Note: this is a repost of a Facebook status I wrote off the cuff about a year ago, lightly edited. As such it has a different style from my other posts, but I still wanted to put it somewhere where it’d be easier to find and share than Facebook.
Gradient descent, in its simplest where you just subtract the gradient of your loss function 
This observation can be used to reinvent the learning rate, which, for dimensional consistency, must have units of length squared. It also suggests that the learning rate ought to be set to something like 

It might also make sense to give different parameters different units, which suggests furthermore that one might want a different learning rate for each parameter, or at least that one might want to partition the parameters into different subsets and choose different learning rates for each.
Going much further, from an abstract coordinate-free point of view the extra information you need to compute the gradient of a smooth function is a choice of (pseudo-)Riemannian metric on parameter space, which if you like is a gigantic hyperparameter you can try to optimize. Concretely this amounts to a version of preconditioned gradient descent where you allow yourself to multiply the gradient (in the coordinate-dependent sense) by a symmetric (invertible, ideally positive definite) matrix which is allowed to depend on the parameters. In the first paragraph this matrix was a constant scalar multiple of identity and in the third paragraph this matrix was constant diagonal.
This is an extremely general form of gradient descent, general enough to be equivariant under arbitrary smooth change of coordinates: that is, if you do this form of gradient descent and then apply a diffeomorphism to parameter space, you are still doing this form of gradient descent, with a different metric. For example, if you pick the preconditioning matrix to be the inverse Hessian (in the usual sense, assuming it’s invertible), you recover Newton’s method. This corresponds to choosing the metric at each point to be given by the Hessian (in the usual sense), which is the choice that makes the Hessian (in the coordinate-free sense) equal to the identity. This is a precise version of “the length at which the curvature of
In general it’s expensive to compute the inverse Hessian, so a more practical thing to do is to use a matrix which approximates it in some sense. And now we’re well on the way towards quasi-Newton methods.
Posted in math.NA | Tagged machine learning | 4 Comments »
In this post we’ll describe the representation theory of the additive group scheme 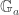

Posted in math.AG, math.RT | Tagged finite fields, group actions | 5 Comments »
As a warm-up to the subject of this blog post, consider the problem of how to classify 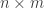
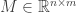
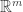

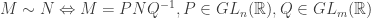
It turns out that the equivalence class of 
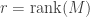
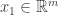

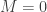
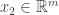
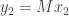
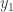
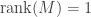
Continuing in this way, we construct vectors 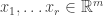
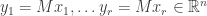


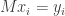
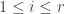
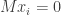
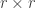
Explicitly, this means we can write
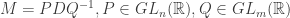
where 
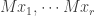

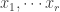
Conceptually, the question we’ve asked is: what does a linear transformation 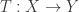


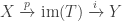
where 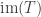

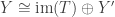

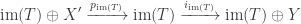
of a projection onto a direct summand and an inclusion of a direct summand. So the only basis-independent information contained in
The actual problem this blog post is about is more interesting: it is to classify
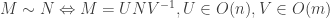
Conceptually, we’re now asking: what does a linear transformation 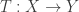
Posted in math.SP | 4 Comments »
Let 
The answer is that we can think of the Morita 2-category as a 2-category of module categories over the symmetric monoidal category 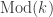
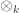
- objects are the categories
, where
is a
- morphisms are cocontinuous
, and
- 2-morphisms are natural transformations.
An equivalent way to describe the morphisms is that they are “
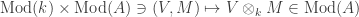
This action comes from taking the adjoint of the enrichment of
So Morita theory can be thought of as a categorified version of module theory, where we study modules over
Posted in math.AG, math.CT | Tagged 2-categories | 2 Comments »
I was staring at a bonfire on a beach the other day and realized that I didn’t understand anything about fire and how it works. (For example: what determines its color?) So I looked up some stuff, and here’s what I learned.
Posted in physics.quant-ph | 9 Comments »
In the previous post we described a fairly straightforward argument, using generating functions and the saddle-point bound, for giving an upper bound
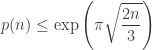
on the partition function 
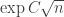

The starting point is to think of a partition of 
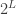

Posted in math.CO | Tagged asymptotics | Leave a Comment »
(Part I of this post is here)
Let

This is a major plot point in the new Ramanujan movie, where Ramanujan conjectures this result and MacMahon challenges him by agreeing to compute 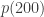
Posted in math.CA, math.CO | Tagged asymptotics | 6 Comments »
Recent Comments
Pete on Ideals and the category of com… Anonymous on Fixed points of random pe… Felix Pahl on Introduction to string di… Amandeep Amandeep on Affine varieties and regular… ZW on The double commutant theo… Categories
Archives
- November 2020
- September 2020
- February 2018
- November 2017
- March 2017
- May 2016
- March 2016
- December 2015
- November 2015
- October 2015
- May 2015
- April 2015
- March 2015
- November 2014
- October 2014
- June 2014
- April 2014
- December 2013
- October 2013
- September 2013
- July 2013
- June 2013
- May 2013
- April 2013
- March 2013
- February 2013
- November 2012
- October 2012
- September 2012
- August 2012
- July 2012
- June 2012
- May 2012
- April 2012
- March 2012
- February 2012
- January 2012
- December 2011
- November 2011
- October 2011
- August 2011
- July 2011
- June 2011
- April 2011
- March 2011
- February 2011
- January 2011
- December 2010
- November 2010
- October 2010
- September 2010
- August 2010
- July 2010
- June 2010
- May 2010
- April 2010
- March 2010
- February 2010
- January 2010
- December 2009
- November 2009
- October 2009
- September 2009
- August 2009
- July 2009
- June 2009
- May 2009
- April 2009
- January 2009
Tag Cloud
2-categories adjoint functors asymptotics Catalan numbers characteristic classes cobordism cohomology Coxeter groups diagrammatic algebra dualizable objects Dynkin diagrams elliptic curves enriched categories Euler characteristic finite fields fixed point theorems Fourier transforms genera generating functions group actions groupoids Hecke algebras Lawvere theories MaBloWriMo machine learning MathOverflow modular forms moments monads monoidal categories Nullstellensatz partition functions pedagogy philosophy of mathematics profinite groups q-analogues quantization quantum groups quaternions self-reference species theory symmetric functions ultrafilters universal properties walks on graphs Young tableaux zeta functions
