In the previous post we used the Polya enumeration theorem to give a sneaky, underhanded proof that
 .
.
If you’ve never seen the exponential function used like this, you might be wondering how it can be “explained.”
To explore this question, I’d like to give three other proofs of this result, the last of which will be “direct.” Along the way I’ll be attempting to describe some basic principles of species theory in an informal way. I’ll also give some applications, including to a Putnam problem.
Proof 1
Possibly the least satisfying proof is computation: write the RHS as

and expand by power series, giving

This implies that the number of permutations of  elements with cycle decomposition
elements with cycle decomposition  (and remember,
(and remember, 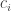 is the number of cycles of size
is the number of cycles of size  , not the size of a cycle) with should be equal to
, not the size of a cycle) with should be equal to
 .
.
If we can prove this directly, we’ll have proven the desired identity. The proof is actually not so bad: just write down 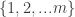 in some order to start with. There are
in some order to start with. There are 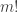 ways to do this. Now we declare this to be a permutation of the desired cycle type by saying that the first
ways to do this. Now we declare this to be a permutation of the desired cycle type by saying that the first 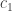 numbers are the fixed points, the next
numbers are the fixed points, the next 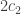 entries are the cycles of length
entries are the cycles of length  (in adjacent pairs), the next
(in adjacent pairs), the next  entries are the cycles of length
entries are the cycles of length  (in adjacent triplets), and so forth. This description is not unique due to the following two symmetries.
(in adjacent triplets), and so forth. This description is not unique due to the following two symmetries.
- The cycles of a given length could have been written down in another order, i.e.
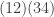 is the same as
is the same as 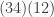 . This means that for each we have overcounted by a factor of
. This means that for each we have overcounted by a factor of 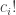 .
.
- The entries in a given cycle could have been written down in another cyclic order, i.e.
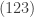 is the same as
is the same as 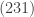 . This means that for each we have overcounted by a factor of
. This means that for each we have overcounted by a factor of  .
.
And we have proven the desired result. If you’d like, try to rephrase this proof in terms of group actions.
This proof is highly unsatisfying. Among other things, it casts a lot of suspicion on the exponential function: all those factorials must be there for a combinatorial reason related to permutations. And considering the denominators of  in the argument of the exponential originally came from the power series of the logarithm, those must be there for a combinatorial reason as well, related to cycles. A starting point as to the exact connection is the following: setting
in the argument of the exponential originally came from the power series of the logarithm, those must be there for a combinatorial reason as well, related to cycles. A starting point as to the exact connection is the following: setting  gives
gives

which is the “obvious” statement that  . But what the combinatorics is telling us is that this analytic identity is equivalent to the existence of cycle decompositions.
. But what the combinatorics is telling us is that this analytic identity is equivalent to the existence of cycle decompositions.
Proof 2
A general technique for dealing with a difficult sequence defined combinatorially is to find a recursion for it. The cycle index polynomials for the symmetric groups can be computed recursively as follows: in a permutation in  , the number
, the number 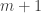 belongs to a cycle of some length
belongs to a cycle of some length 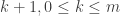 . The rest of the cycles can be identified with a permutation in
. The rest of the cycles can be identified with a permutation in 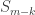 once we choose which elements of to identify with the subset of size
once we choose which elements of to identify with the subset of size  , and in what order. After juggling the factorials, this argument is equivalent to the weighted identity
, and in what order. After juggling the factorials, this argument is equivalent to the weighted identity

since what we have shown is that each monomial on the LHS comes from a unique term on the RHS. Dividing out, this is equivalent to

but this is equivalent to

and solving this differential equation with the appropriate initial conditions gives us the same identity as before. Recognizing multiplication by the index as differentiation and sums of the form on the RHS as multiplication of series is a common trick, and it’s good to get used to it.
But the manner of this proof suggests a more general argument: it’s true of any power series of the form  that
that

and if we understood the combinatorial meaning of differentiation this would give a recursive description of the combinatorial meaning of 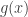 .
.
Proof 3
The proofs so far all lack real explanatory power. To understand this result from a purely combinatorial point of view, it is necessary to appeal to the theory of exponential, rather than ordinary, generating functions. Exponential generating functions take the form

for some combinatorial sequence  , and they appear when counting so-called “labeled” objects. The precise definition of “labeled” is surprisingly difficult to pin down; for one thing, one should be very careful not to think of a labeling of a set as defining an ordering, although most of the symbols we use to label things come with an implicit order.
, and they appear when counting so-called “labeled” objects. The precise definition of “labeled” is surprisingly difficult to pin down; for one thing, one should be very careful not to think of a labeling of a set as defining an ordering, although most of the symbols we use to label things come with an implicit order.
One way to understand what “labeled” objects are is in terms of what multiplication of egfs does. Multiplication of ogfs corresponds to the convolution or Cauchy product
 .
.
As we’ve discussed, Cauchy products appear commonly in combinatorics when  describe the number of ways to perform some construction on a set of size
describe the number of ways to perform some construction on a set of size  ; then
; then  describes the number of ways to perform the first construction on the “left half” of that set and the second construction on the “right half” of that set, for some division of left and right.
describes the number of ways to perform the first construction on the “left half” of that set and the second construction on the “right half” of that set, for some division of left and right.
Multiplication of egf’s appears when, instead of dividing left and right (which is typical if you’re constructing totally ordered objects like tilings), you want to perform the first construction on an arbitrary subset and the second construction on its complement (which is typical if you’re constructing unordered objects like labeled graphs); that is, if

then their product 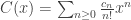 satisfies
satisfies
 .
.
For example, the sequence with constant value  has the ogf
has the ogf 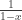 . One usually interprets this as the “sequence” construction: there is exactly one board with slots for each . Squaring this generating function gives the number of ways to place two boards next to each other, counted by the total number of slots; in other words, it’s the number of ways to divide a board into a left side and a right side.
. One usually interprets this as the “sequence” construction: there is exactly one board with slots for each . Squaring this generating function gives the number of ways to place two boards next to each other, counted by the total number of slots; in other words, it’s the number of ways to divide a board into a left side and a right side.
The sequence with constant value has the egf 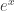 . One usually interprets this as the “set” construction – this is very important for understanding the cycle index result – but this is vague; a concrete perspective is that there is exactly one empty graph with vertices for each . (This perspective is useful because many labeled constructions are best thought of as constructing various types of labeled graphs.) Squaring this generating function gives the number of ways to put two empty graphs together, counted by the total number of vertices; in other words, it’s the number of ways to divide an empty graph into red vertices and blue vertices.
. One usually interprets this as the “set” construction – this is very important for understanding the cycle index result – but this is vague; a concrete perspective is that there is exactly one empty graph with vertices for each . (This perspective is useful because many labeled constructions are best thought of as constructing various types of labeled graphs.) Squaring this generating function gives the number of ways to put two empty graphs together, counted by the total number of vertices; in other words, it’s the number of ways to divide an empty graph into red vertices and blue vertices.
I hope that example gave you some insight into what I mean by working with “labeled” objects; when we put objects together, we have to relabel them appropriately for everything to make sense. Even when working with ogfs we already do this when defining the disjoint union.
Given the above definition of the exponential, why is it true that
 ?
?
This may seem silly, but bear with me. On egfs, differentiation takes a sequence to 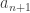 and deletes the first term. Combinatorially, it can be thought of as follows: if describes the number of ways to perform a certain construction on the empty graph on vertices, then differentiation corresponds to adding a new vertex, then performing the construction. So the reason the exponential function is its own derivative is that adding a new vertex and performing the empty graph construction is equivalent to the empty graph construction. Now something less trivial: why is it true that
and deletes the first term. Combinatorially, it can be thought of as follows: if describes the number of ways to perform a certain construction on the empty graph on vertices, then differentiation corresponds to adding a new vertex, then performing the construction. So the reason the exponential function is its own derivative is that adding a new vertex and performing the empty graph construction is equivalent to the empty graph construction. Now something less trivial: why is it true that
 ?
?
Well, 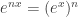 describes the number of ways to color an empty graph in colors and adding a new vertex, then performing this construction is the same thing as performing this construction, then adding a new vertex of one of the colors.
describes the number of ways to color an empty graph in colors and adding a new vertex, then performing this construction is the same thing as performing this construction, then adding a new vertex of one of the colors.
More generally, let ; why is it true that
?
In order for this result to make sense “formally” we require that 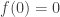 ; all this means is that the corresponding construction can’t do anything without any vertices. Combinatorially, what the above equation says is that adding a new vertex and performing the
; all this means is that the corresponding construction can’t do anything without any vertices. Combinatorially, what the above equation says is that adding a new vertex and performing the  -construction is the same thing as performing the -construction on some subset together with adding a new vertex and performing the
-construction is the same thing as performing the -construction on some subset together with adding a new vertex and performing the  -construction on what’s left.
-construction on what’s left.
This is a recursive definition. One way to think about it is that differentiation “points” to a vertex (although the pointing operation is usually given by  ), and “pointing” to a -construction points out a subset equivalent to an -construction. In other words, since describes empty graphs on vertices,
), and “pointing” to a -construction points out a subset equivalent to an -construction. In other words, since describes empty graphs on vertices, 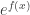 describes the total number of ways to replace each vertex with an -construction (which again one can think of as another type of graph, and then we count according to the total number of vertices). A great intuition for thinking about this is to look at it the other way around: if denotes a construction such that
describes the total number of ways to replace each vertex with an -construction (which again one can think of as another type of graph, and then we count according to the total number of vertices). A great intuition for thinking about this is to look at it the other way around: if denotes a construction such that 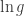 has a “nice” generating function, then denotes the connected components of -constructions. (In my previous post on this subject I explained how this leads to the generating function for connected labeled graphs.)
has a “nice” generating function, then denotes the connected components of -constructions. (In my previous post on this subject I explained how this leads to the generating function for connected labeled graphs.)
It’s also possible to interpret the series

in this manner, since 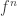 denotes the number of ways to split up a set into subsets and perform the -construction on each one. The reason we divide by
denotes the number of ways to split up a set into subsets and perform the -construction on each one. The reason we divide by 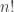 is related to relabeling: if we think of each -construction as having a different color to distinguish them, then the division by corresponds to ignoring the different ways to label each color. One can think of this as a certain action of the symmetric group, but with the property that the labelings of the vertices prevent any constructions from having a nontrivial stabilizer.
is related to relabeling: if we think of each -construction as having a different color to distinguish them, then the division by corresponds to ignoring the different ways to label each color. One can think of this as a certain action of the symmetric group, but with the property that the labelings of the vertices prevent any constructions from having a nontrivial stabilizer.
Finally, here’s a combinatorial proof that  . Since
. Since  denotes “do an -construction or a -construction,”
denotes “do an -construction or a -construction,” 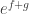 denotes the number of collections of either or -constructions, which can be uniquely decomposed into the subset consisting of -constructions and the subset consisting of -constructions.
denotes the number of collections of either or -constructions, which can be uniquely decomposed into the subset consisting of -constructions and the subset consisting of -constructions.
So what we have now are various purely combinatorial explanations of the properties of the exponential function. Are they enough to explain the cycle index result directly?
Yes! The key is to identify a permutation with its functional graph; see the Topological Musings post I linked to for another discussion of this technique. This is a graph whose vertex set is the set we’re permuting together with directed arrows from  to
to  whenever
whenever  .
.
The identifying property of a functional graph is that every vertex has out-degree , and since permutations are invertible every vertex also has in-degree . It’s not hard to see from here that the connected components of the functional graph of a permutation are directed cycles, which we already knew, but not in this language.
Here’s how to construct the generating function for directed cycles: start with vertices. List the vertices in some order and then connect them in that order, then connect the last vertex to the first vertex. There are ways to do this. Then divide by because we pretended that there was a start vertex when there wasn’t. So the generating function for directed cycles is

just like we already knew from calculus. (Again, this proof is purely combinatorial.) But we know more: since the coefficient of 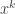 means exactly “the cycles of length
means exactly “the cycles of length  ,” we can add a parameter for every coefficient and construct
,” we can add a parameter for every coefficient and construct
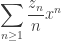
where 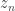 is the parameter controlling the cycles of length , and taking the exponential of this generating function gives us precisely (the functional graphs of) permutations, with parameters that record how many cycles of each length they have – precisely the cycle index polynomials of the symmetric groups.
is the parameter controlling the cycles of length , and taking the exponential of this generating function gives us precisely (the functional graphs of) permutations, with parameters that record how many cycles of each length they have – precisely the cycle index polynomials of the symmetric groups.
What may not be obvious at this moment is just how much control having all those parameters around entails.
Application 1
Suppose we only want to count permutations indexed by how many cycles of length they have, i.e. fixed points. So we ignore every parameter except the first one, giving

which has the exponential
 .
.
By construction,  is a polynomial such that the coefficient of
is a polynomial such that the coefficient of  records the number of permutations with fixed points; these numbers are known as the rencontres numbers, and this generating function tells you everything you could want to know about them. Setting
records the number of permutations with fixed points; these numbers are known as the rencontres numbers, and this generating function tells you everything you could want to know about them. Setting  tells us that derangements have generating function
tells us that derangements have generating function
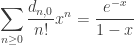
which, after expansion, implies the well-known identity
 .
.
The standard proof of this identity is by inclusion-exclusion. Now, counting the number of permutations with fixed points is trivial once you know how to count derangements, and the generating function reflects this: taking the  derivative with respect to and setting it equal to zero gives
derivative with respect to and setting it equal to zero gives

This identity is equivalent to the following: a permutation of elements with fixed points is the same thing as a derangement of 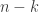 elements, once the appropriate relabeling has been done. Both the generating function identity and the combinatorial proof imply
elements, once the appropriate relabeling has been done. Both the generating function identity and the combinatorial proof imply
 .
.
Writing  implies the identity
implies the identity
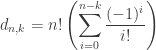
which one can also deduce from the above. This identity trivializes a problem from Canada 1982.
Note that all of these identities are easily provable without using the language of egfs; the value of egfs is that they make proving these identities automatic and generalizable.
One can also see directly from the generating function that  is asymptotically
is asymptotically 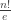 ; this is due to the general principle that a meromorphic function
; this is due to the general principle that a meromorphic function 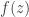 with positive coefficients and dominant singularity a simple pole at
with positive coefficients and dominant singularity a simple pole at 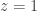 has coefficients asymptotically equal to
has coefficients asymptotically equal to  . Flajolet and Sedgewick exploit this simple principle to the hilt in analyzing generating functions arising from regular languages.
. Flajolet and Sedgewick exploit this simple principle to the hilt in analyzing generating functions arising from regular languages.
What’s the average number of fixed points of a permutation? By the orbit-counting lemma, the answer is the number of orbits of the action of  on elements, which is just . One can also see this by differentiating the above generating function with respect to and letting
on elements, which is just . One can also see this by differentiating the above generating function with respect to and letting 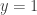 , which gives
, which gives
 .
.
What’s the average value of the square of the number of fixed points? This is less obvious. There is a nontrivial combinatorial argument that generalizes to powers, but again with egfs it’s automatic: take the second derivative, which gives the average value of  , then add the previous generating function. This generating function is
, then add the previous generating function. This generating function is
 .
.
Some perspectives on the generalization are available here. In any case, generating functions in general make it quite easy to compute means and variances of various combinatorial parameters of interest. For example, the above computation implies that the variance of the number of fixed points is .
Application 2
Now an application to a nontrivial Putnam problem.
Putnam 2005 B6: Let  denote the signature of the permutation
denote the signature of the permutation  . Show that
. Show that
 .
.
Solution. Fans of generating functions are fond of exploiting the identity
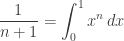 .
.
In keeping with the combinatorial theme of this post, this identity has the following probabilistic interpretation: pick ![x \in [0, 1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=333333&s=0&c=20201002) uniformly and pick other points. The RHS is the probability that the points are all to the left of . The LHS is the probability that the first point chosen, , is to the right of all the other points, which is just the reciprocal of the total number of points. Anyway, exploiting this identity we find that what we really want to compute is
uniformly and pick other points. The RHS is the probability that the points are all to the left of . The LHS is the probability that the first point chosen, , is to the right of all the other points, which is just the reciprocal of the total number of points. Anyway, exploiting this identity we find that what we really want to compute is
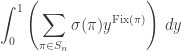
and this is much more manageable: the polynomial we’re integrating happens to be easily computable from the cycle index polynomial  . Since the signature is multiplicative, it is determined by the cycle decomposition of a permutation. Moreover, the parity of the number of elements of a cycle is precisely the opposite of the signature of the cycle; it then follows that
. Since the signature is multiplicative, it is determined by the cycle decomposition of a permutation. Moreover, the parity of the number of elements of a cycle is precisely the opposite of the signature of the cycle; it then follows that
 .
.
This is equal to  . Integrating with respect to , we obtain
. Integrating with respect to , we obtain
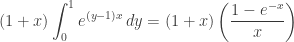 .
.
From here it’s a straightforward computation; the coefficient of 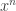 is indeed
is indeed  as desired.
as desired.
What is somewhat mysterious is that this problem has the following beautiful alternate solution:
 .
.
One can then induct using row reduction. The appearance of determinants in combinatorics is fascinating and not, it seems to me, fully understood.
Application 3
The following folklore problem is intimately related to cycle decomposition. There are 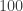 prisoners in a jail. One day the warden decides to play the following game: he places the names of the prisoners into boxes in a row in a room and instructs each prisoner to enter the room. Each prisoner is allowed to check up to
prisoners in a jail. One day the warden decides to play the following game: he places the names of the prisoners into boxes in a row in a room and instructs each prisoner to enter the room. Each prisoner is allowed to check up to 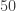 of the boxes. If each prisoner finds his name in this manner, the prisoners are allowed free. Assuming a random distribution of names, what is the optimal strategy and what is the corresponding probability that it succeeds?
of the boxes. If each prisoner finds his name in this manner, the prisoners are allowed free. Assuming a random distribution of names, what is the optimal strategy and what is the corresponding probability that it succeeds?
Naively, one would expect that each prisoner has a  chance of finding his name, which gives a dismal success probability of
chance of finding his name, which gives a dismal success probability of  . The actual probability of success for the optimal strategy is around
. The actual probability of success for the optimal strategy is around 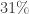 . Why?
. Why?
The key is that one can impose a total order on the set of boxes and on the set of names – for example, by calling them both  – and then what the warden hands us is a random permutation, and permutations have certain structural properties. Although the proof of the optimality of the following strategy is difficult, its description is simple:
– and then what the warden hands us is a random permutation, and permutations have certain structural properties. Although the proof of the optimality of the following strategy is difficult, its description is simple:
- Prisoner begins at box . If box contains name
 , move to box .
, move to box .
- Each prisoner continues in this manner until either boxes have been checked or the prisoner finds his name.
In other words, the prisoner checks the first entries of whichever cycle he’s in. From here, the probability of success is simply the probability that each cycle has length at most , which is much better than . This probability is precisely the coefficient of  in
in
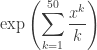
and computer algebra systems are very good at this sort of computation. (Note that differentiation, again, gives a recurrence.) Asymptotic techniques are available, but I don’t think the easy asymptotics kick in at  and I’m not familiar with the hard asymptotics.
and I’m not familiar with the hard asymptotics.
In the other direction, one can compute the probability that a given permutation contains no cycles of length less than or equal to  ; this is given by the generating function
; this is given by the generating function
 .
.
(Expanding this out gives a rather complicated identity which can presumably be proven by inclusion-exclusion.) The probability we want is, in the regime that is large compared to , approximately the residue at  , which is
, which is 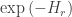 where
where  is a harmonic number. If grows sufficiently slowly as gets large,
is a harmonic number. If grows sufficiently slowly as gets large,  where
where  is the Euler-Mascheroni constant, which gives the asymptotic probability
is the Euler-Mascheroni constant, which gives the asymptotic probability 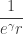 .
.
Remarks
There are (at least) two “deep” explanations for the factorials in exponential generating functions, neither of which I understand particularly well. One proceeds via Rota’s idea that many combinatorial arguments naturally generalize to posets. Ordinary generating functions correspond to the poset  under the usual order, exponential generating functions correspond to the poset of finite sets under inclusion, and, for example, Dirichlet series correspond to the poset under division. Rota’s Finite Operator Calculus is the only reference I know on this subject.
under the usual order, exponential generating functions correspond to the poset of finite sets under inclusion, and, for example, Dirichlet series correspond to the poset under division. Rota’s Finite Operator Calculus is the only reference I know on this subject.
One advantage of this perspective is that it unifies various notions of Mobius inversion. Mobius inversion on under the usual order corresponds to the inversion pair

which in turn corresponds to the generating function identity
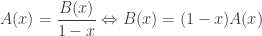 .
.
Mobius inversion on finite sets corresponds to the inversion pair

which in turn corresponds to the generating function identity
 .
.
This is a disguised form of inclusion-exclusion! Unfortunately, I don’t have my copy of Enumerative Combinatorics handy to make sure I state the exact connection correctly.
Mobius inversion on under division is the usual number-theoretic notion of Mobius inversion; it corresponds to the inversion pair

where  is the number-theoretic Mobius function, which in turn corresponds to the generating function identity
is the number-theoretic Mobius function, which in turn corresponds to the generating function identity

where  is the Riemann zeta function. Motivated by the number-theoretic case, the generalization of the functions and is called the zeta function of the poset in question, and the generalization of their inverses is called the Mobius function of the poset. I haven’t, however, read through Rota’s text very thoroughly, so I can’t discuss this fascinating idea in detail.
is the Riemann zeta function. Motivated by the number-theoretic case, the generalization of the functions and is called the zeta function of the poset in question, and the generalization of their inverses is called the Mobius function of the poset. I haven’t, however, read through Rota’s text very thoroughly, so I can’t discuss this fascinating idea in detail.
The other way to make sense of the factorials in egfs, which I haven’t seen fully fleshed out anywhere, treats division by as what’s called a weak quotient by the symmetric group. The idea is to define a notion of quotient of a set  by a group
by a group  acting on it such that elements of the set with nontrivial stabilizer are “folded in half” (or times) to count for less. I wish I could find more resources about this sort of stuff.
acting on it such that elements of the set with nontrivial stabilizer are “folded in half” (or times) to count for less. I wish I could find more resources about this sort of stuff.
Exercises
Show, for fixed , that the probability that a permutation of elements consists of only cycles of length at most vanishes as becomes large.
Compute the generating function of the complete Bell polynomials.
Given a graph , let 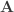 denote its adjacency matrix and let
denote its adjacency matrix and let 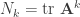 denote the number of closed walks of length . Show that
denote the number of closed walks of length . Show that
 .
.
This function is (a variant of) the Ihara zeta function of . (The purely manipulative proof of this identity is a consequence of a result in the last post; what would be great is a combinatorial proof.)
Let  be an ordinary, not exponential, generating function describing some collection of objects. Show that the generating function for unordered pairs of distinct objects from this collection is
be an ordinary, not exponential, generating function describing some collection of objects. Show that the generating function for unordered pairs of distinct objects from this collection is
 .
.
(Note what happens when 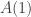 is finite.) Hence solve the following problem.
is finite.) Hence solve the following problem.
Putnam 2003 A6: for a set of non-negative integers let  denote the number of ordered pairs
denote the number of ordered pairs  such that
such that  . Is it possible to partition the non-negative integers into disjoint sets
. Is it possible to partition the non-negative integers into disjoint sets  and
and  such that
such that 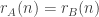 for all ?
for all ?
Similarly, show that the generating function for unordered triplets of distinct objects from this collection is
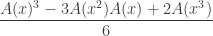 .
.
Generalize. (The easiest way to do this, as usual, is to pack everything into a bigger generating function. If you get stuck, compute the first few cycle index polynomials of the symmetric groups.)

[…] on elements. These are precisely the permutations consisting of cycles of length or , so the exponential formula gives an exponential generating […]
[…] is a familiar application of the exponential formula as it was given in this blog post, as a statement about the cycle index polynomials of the symmetric […]
[…] didn’t make this explicit, is that this maneuver opens up the possibility of appealing to the exponential formula. Loosely speaking, the exponential formula can be interpreted as saying that if some exponential […]
[…] to permutations. By the exponential formula, letting denote the number of cycles of length in a permutation , we […]
[…] Proof 2. By the exponential formula, […]
[…] combinatorial approach is through the exponential formula, or at least through what we know about the cycle index polynomials of the symmetric groups. If we write , then we know […]
[…] At Annoying Precision, a project aimed at the “Generally Interested Lay Audience” that Qiaochu Yuan started aims “to build up to a discussion of the Polya enumeration theorem without assuming any prerequisites other than a passing familiarity with group theory.” It begins with GILA I: Group Actions and Equivalence Relations, the last post of the series being GILA VI: The cycle index polynomials of the symmetric groups. […]