Let 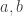 be two
be two  matrices. If don’t commute, then
matrices. If don’t commute, then  ; however, the two share several properties. If either
; however, the two share several properties. If either  or
or  is invertible, then
is invertible, then 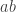 is conjugate to
is conjugate to  , so in particular they have the same characteristic polynomial.
, so in particular they have the same characteristic polynomial.
What if neither nor are invertible? As it turns out, and still have the same characteristic polynomial, although they are not conjugate in general (e.g. we might have  but nonzero). There are several ways of proving this result, which implies in particular that and have the same eigenvalues.
but nonzero). There are several ways of proving this result, which implies in particular that and have the same eigenvalues.
What if are linear transformations on an infinite-dimensional vector space? Do and still have the same eigenvalues in an appropriate sense? As it turns out, the answer is yes, and the key lemma in the proof is an interesting piece of “noncommutative high school algebra.”
Square matrices
Proposition: Let be two matrices over an algebraically closed field  . Then and have the same characteristic polynomial.
. Then and have the same characteristic polynomial.
(Note that this is a polynomial identity in the entries of regarded as 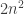 formal variables, so to prove it identically (in particular for all commutative rings
formal variables, so to prove it identically (in particular for all commutative rings  ) it suffices to prove it over a fixed algebraically closed field, e.g. we could take
) it suffices to prove it over a fixed algebraically closed field, e.g. we could take 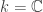 .)
.)
Proof 1. This is clear if is invertible since  . The invertible matrices are Zariski-dense in all matrices (when they are also dense in the usual topology), so the result follows in general.
. The invertible matrices are Zariski-dense in all matrices (when they are also dense in the usual topology), so the result follows in general.
Proof 2. Recall that 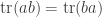 . (This is straightforward to prove by computation but it also has an elegant proof using the invariant description of the trace as tensor contraction
. (This is straightforward to prove by computation but it also has an elegant proof using the invariant description of the trace as tensor contraction  , and one can also prove it in the same way as above.) By induction we conclude that
, and one can also prove it in the same way as above.) By induction we conclude that 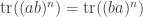 for all
for all  , so the power sum symmetric polynomials in the eigenvalues of and are identical. By the Newton-Girard identities, it follows that the elementary symmetric polynomials in the eigenvalues of and are identical.
, so the power sum symmetric polynomials in the eigenvalues of and are identical. By the Newton-Girard identities, it follows that the elementary symmetric polynomials in the eigenvalues of and are identical.
(Edit, 10/25/17:) Proof 2 only works over a field of characteristic zero. Fixing it basically gives a version of Proof 3.
Proof 3. We work universally. Let the entries of be formal variables  in a polynomial ring
in a polynomial ring ![\mathbb{Z}[a_{ij}, b_{ij}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5Ba_%7Bij%7D%2C+b_%7Bij%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Note that we have
. Note that we have
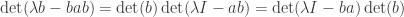
where  is another (scalar) variable and
is another (scalar) variable and  is the identity matrix. Since is an integral domain, we can cancel
is the identity matrix. Since is an integral domain, we can cancel  from both sides to obtain
from both sides to obtain
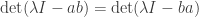 .
.
Eigencomplications
What can we say beyond matrices? It might be reasonable to guess that and still have the same eigenvalues if are linear transformations on an infinite-dimensional vector space; however, since no analogue of the characteristic polynomial, the trace, or the determinant is available in general in this setting, the proofs above don’t generalize, and in fact the result is false.
Example. Consider the differential operators  and
and 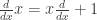 acting on
acting on ![k[x]](https://s0.wp.com/latex.php?latex=k%5Bx%5D&bg=ffffff&fg=333333&s=0&c=20201002) ( a field of characteristic zero). The former has eigenvectors
( a field of characteristic zero). The former has eigenvectors 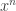 with eigenvalues while the latter has eigenvectors with eigenvalues
with eigenvalues while the latter has eigenvectors with eigenvalues  ; thus the eigenvalues of the former are
; thus the eigenvalues of the former are 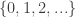 while the eigenvalues of the latter are
while the eigenvalues of the latter are  .
.
 and
and 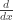 provide examples of other infinite-dimensional phenomena too: they are endomorphisms of a vector space like matrices, but one is injective without being surjective, one is surjective without being injective, and doesn’t have any eigenvectors whatsoever (even if is algebraically closed)!
provide examples of other infinite-dimensional phenomena too: they are endomorphisms of a vector space like matrices, but one is injective without being surjective, one is surjective without being injective, and doesn’t have any eigenvectors whatsoever (even if is algebraically closed)!
The issue that occurs in the above example is the following. Let be two linear operators on a vector space  . Suppose that
. Suppose that  is an eigenvector for , thus
is an eigenvector for , thus

for some . Then
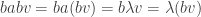
so that  is an eigenvector for with the same eigenvalue, unless it is equal to zero. But in that case
is an eigenvector for with the same eigenvalue, unless it is equal to zero. But in that case  , so
, so 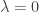 . If
. If  , then this cannot occur. So we have proven the following.
, then this cannot occur. So we have proven the following.
Proposition: Let be two linear transformations on a vector space . Then is a nonzero eigenvalue of if and only if it is a nonzero eigenvalue of .
Thus the only possible discrepancy in the sets of eigenvalues occurs when , and the example of  shows that this can occur.
shows that this can occur.
Unfortunately, as we have seen, if is infinite-dimensional there are linear transformations with no eigenvectors whatsoever, such as acting on . Is there no hope of generalizing the above result to such linear transformations?
The spectrum
When we talk about eigenvalues, what are we really talking about? On a finite-dimensional vector space , to say that a linear transformation 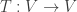 has an eigenvector with eigenvalue is to say that
has an eigenvector with eigenvalue is to say that  , or
, or  . This is true if and only if
. This is true if and only if 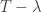 fails to be invertible, which suggests the following definition.
fails to be invertible, which suggests the following definition.
Definition: Let be a linear transformation on a vector space over a field . The spectrum  consists of all
consists of all 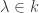 such that
such that 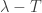 is not invertible.
is not invertible.
If is not invertible because it is not injective, then is an eigenvalue; in functional analysis terms, lies in the point spectrum 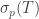 . However, may also fail to be invertible because it is not surjective, and in this case the spectrum is strictly larger than the point spectrum.
. However, may also fail to be invertible because it is not surjective, and in this case the spectrum is strictly larger than the point spectrum.
Example. The linear operator acting on has spectrum all of even though it has no point spectrum.
Example. The linear operator acting on 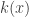 has empty spectrum.
has empty spectrum.
Example. Let  be a topological space,
be a topological space,  be the space of continuous functions
be the space of continuous functions 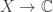 , and let
, and let  be multiplication by some function
be multiplication by some function 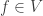 . Then the spectrum of
. Then the spectrum of 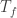 is precisely the range of
is precisely the range of  . (This is one basic reason it’s reasonable to think of eigenvalues of operators in quantum mechanics as being values of functions such as position and momentum.) In many cases, has no point spectrum (e.g.
. (This is one basic reason it’s reasonable to think of eigenvalues of operators in quantum mechanics as being values of functions such as position and momentum.) In many cases, has no point spectrum (e.g. ![X = [0, 1], f = x](https://s0.wp.com/latex.php?latex=X+%3D+%5B0%2C+1%5D%2C+f+%3D+x&bg=ffffff&fg=333333&s=0&c=20201002) ).
).
There is a nice connection between spectra in this sense and spectra of rings in algebraic geometry. A simple version is as follows. If is a linear transformation of a finite-dimensional vector space over an algebraically closed field , then we can consider the ring ![k[T]](https://s0.wp.com/latex.php?latex=k%5BT%5D&bg=ffffff&fg=333333&s=0&c=20201002) generated by
generated by  in
in 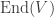 . This ring is isomorphic to
. This ring is isomorphic to ![k[x]/m(x)](https://s0.wp.com/latex.php?latex=k%5Bx%5D%2Fm%28x%29&bg=ffffff&fg=333333&s=0&c=20201002) where
where  is the minimal polynomial of , so the spectrum of can naturally be identified with the set of eigenvalues (that is, the spectrum) of !
is the minimal polynomial of , so the spectrum of can naturally be identified with the set of eigenvalues (that is, the spectrum) of !
A more general connection can be obtained by generalizing the definition of spectrum.
Definition: Let be a field and a -algebra. Let 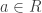 . The spectrum
. The spectrum  of consists of all such that
of consists of all such that  is not invertible in .
is not invertible in .
(We recover the definition applied to linear operators by taking 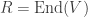 .)
.)
Now observe that if is commutative, then is not invertible if and only if it is contained in a maximal ideal . This maximal ideal has the property that 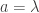 in
in  , thus thinking of as a function on
, thus thinking of as a function on 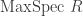 it follows that takes on every value in its spectrum at an appropriate maximal ideal! If the residue fields of are all (which occurs for example if is algebraically closed and is finitely-generated by the Nullstellensatz) then the converse is also true.
it follows that takes on every value in its spectrum at an appropriate maximal ideal! If the residue fields of are all (which occurs for example if is algebraically closed and is finitely-generated by the Nullstellensatz) then the converse is also true.
We are now ready to state the appropriate generalization of the proposition above about characteristic polynomials.
Proposition: Let be two elements of a -algebra . Then 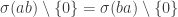 .
.
The crucial lemma
The proposition claims that if is nonzero, then  is invertible if and only if
is invertible if and only if  is invertible. Equivalently,
is invertible. Equivalently, 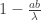 is invertible if and only if
is invertible if and only if 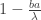 is invertible. By setting
is invertible. By setting  , we see that the following piece of “noncommutative high school algebra” implies and in fact generalizes our proposition.
, we see that the following piece of “noncommutative high school algebra” implies and in fact generalizes our proposition.
Lemma: Let be elements of a ring . Then 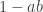 is invertible if and only if
is invertible if and only if 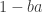 is invertible.
is invertible.
This lemma is somewhat infamous for having the following “proof.” Pretend that it makes sense to write
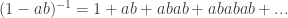
in a general ring. Then
 .
.
And indeed, if we write 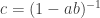 , then we dutifully find that
, then we dutifully find that

and similarly
 .
.
Halmos once posed the problem of explaining in what sense the geometric series proof works. There is a discussion of this problem on MO which I would summarize as follows. The universal ring describing this problem is the free ring

on two elements , and an inverse to . If we show that has an inverse in this ring, then we are done by the universal property. And the idea is that this ring ought to embed in a suitable ring of formal power series where one can make sense of geometric series expansions. To make this easier, we’ll work with a different ring
![\displaystyle R = \mathbb{Z} \langle a, b, c \rangle [t] / (c(1 - tab) - 1, (1 - tab)c - 1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R+%3D+%5Cmathbb%7BZ%7D+%5Clangle+a%2C+b%2C+c+%5Crangle+%5Bt%5D+%2F+%28c%281+-+tab%29+-+1%2C+%281+-+tab%29c+-+1%29&bg=ffffff&fg=333333&s=0&c=20201002)
where  is a new central variable, and we want to embed into
is a new central variable, and we want to embed into ![\mathbb{Z} \langle a, b \rangle [[t]]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D+%5Clangle+a%2C+b+%5Crangle+%5B%5Bt%5D%5D&bg=ffffff&fg=333333&s=0&c=20201002) by sending
by sending  to
to  . In this ring the geometric series argument makes perfect sense and proves that
. In this ring the geometric series argument makes perfect sense and proves that  is an inverse to
is an inverse to  . Applying the evaluation homomorphism out of obtained by setting
. Applying the evaluation homomorphism out of obtained by setting 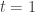 then solves our original problem.
then solves our original problem.
However, it does not seem trivial to me to prove that the natural map from to is actually injective, and nobody in the MO discussion above seems to actually prove this.

Hi Qiaochu, I don’t know if you have any plans to update this. But the rectangular matrix case can be dealt with very easily after having done the square case: see http://math.stackexchange.com/a/332688/22857
In proof 3 for square matrices, you wrote an argument of the form $\det(B) \det(X) = \det(Z) = \det(Y) \det(B)$ and since we work over an integral domain we can cancel $\det(B)$ from both side. Put it in another way $$ \det(B) \cdot ( \det(X)-\det(Y) ) = 0 \ .$$
While the image of the det homomorphism is an integral domain, its domain is not! You can have a non-zero non-invertible matrix $B$ and then $\det(B)=0$ and you can’t say anything about $\det(X)-\det(Y)$. So the proof is valid only when both $A$ and $B$ are invertible (or at least when $A$ and $B$ have a non-zero determinant).
In proof 3 the entries of the matrices are all algebraically independent formal variables; in particular, the determinant is literally the determinant as a polynomial in the entries, and so is definitely nonzero. That’s the benefit of working universally. (That is, in that proof the matrices aren’t particular matrices; they’re literally the universal pair of matrices.)
Very nice post. I just stumbled upon your blog and wanted to mention that I’ve really loved surfing around your weblog posts. After all I will be subscribing to your feed and I hope you write once more very soon!
In proof-3 why is $det(\lambda I – bab) = det(b) det(\lambda I – ab)$?
It’s not, of course! I meant .
.
in proof 3 you missed b in the first determinant:det(b\lambdaI-bab)=det(b)(det(\lambdaI-ab))=det(b)det(\lambdaI-ba). And K[T] is not isomorphic to K[x]/m(x) where m is the charateristic polynomial but to K[x]/p(x) where p is the minimal polynomial(otherwise for example K[Id] would be n dimensional,rather than 1 dimensional)
Thanks! Those were both typos; I meant the minimal polynomial (that’s why I called it !).
!).