Test your intuition: consecutive tails
September 21, 2010 by Qiaochu Yuan
Something very unfortunate has happened: several things I have recently written that could have been blog entries are instead answers on math.SE! In the interest of exposition beyond the Q&A format I am going to “rescue” one of these answers. It is an answer to the following question, which I would like you to test your intuition about:
Flip  coins. What is the probability that, at some point, you flipped at least
coins. What is the probability that, at some point, you flipped at least 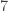 consecutive tails?
consecutive tails?
Jot down a quick estimate; see if you can get within a factor of  or so of the actual answer, which is below the fold.
or so of the actual answer, which is below the fold.
The actual answer, as estimated largely by hand
The actual answer is about  . As Tanya Khovanova observed, when people try to write down sequences of random coin flips, they make certain biased decisions to make the sequences “look” more random. One of the decisions that people make is to underestimate the number and frequency of consecutive heads and tails, which are surprisingly likely. (The original questioner admitted that he expected the answer to be around
. As Tanya Khovanova observed, when people try to write down sequences of random coin flips, they make certain biased decisions to make the sequences “look” more random. One of the decisions that people make is to underestimate the number and frequency of consecutive heads and tails, which are surprisingly likely. (The original questioner admitted that he expected the answer to be around 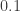 and was not surprised when he misinterpreted my answer and thought the answer was around
and was not surprised when he misinterpreted my answer and thought the answer was around  !)
!)
One way to correct this tendency is think about the expected number of such runs. Our saving grace here is that linearity of expectation holds regardless of whether the random variables involved are independent or not. So the expected number of times you get consecutive tails in coins is just the expected number of times the first coins all come up tails, plus the expected number of times the next coins (as in coins through  ) all come up tails, and so forth – or
) all come up tails, and so forth – or  . So we expect, on average, a little more than one such run of tails, which means they should actually be fairly likely. If I knew more statistics I might even tell you what we expect the distribution of runs of tails to look like in the limit and give an estimate of the probability from there, but I don’t, so I’ll estimate the probability the hard way.
. So we expect, on average, a little more than one such run of tails, which means they should actually be fairly likely. If I knew more statistics I might even tell you what we expect the distribution of runs of tails to look like in the limit and give an estimate of the probability from there, but I don’t, so I’ll estimate the probability the hard way.
First, some generalities. The set of sequences of coin flips in which no more than tails are consecutively flipped is an example of a regular language. Regular languages have a very well-understood enumerative and asymptotic theory; one can either construct a rational generating function from an unambiguous regular expression, or if one is not available, take powers of the adjacency matrix of a finite state machine recognizing the language. In this case the Perron-Frobenius theorem, when applicable, implies that the eigenvalue of the matrix of largest absolute value is positive, real, unique, and has multiplicity  , so that asymptotically the number of words of length
, so that asymptotically the number of words of length  in such a language grows as
in such a language grows as  where
where  is some constant and
is some constant and 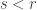 .
.
In this case we can bypass the matrix machinery because the generating function is easy to describe directly. Consider the sequence  describing the number of ways to flip coins such that at no point are there or more tails in a row. Then the number we want to compute is
describing the number of ways to flip coins such that at no point are there or more tails in a row. Then the number we want to compute is 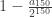 . By appending heads to the beginning of such a sequence, we can decompose any such sequence into the blocks
. By appending heads to the beginning of such a sequence, we can decompose any such sequence into the blocks

in a unique manner. This implies the generating function identity

where we need to shift the index to account for the missing heads at the beginning. (Note that when is replaced by we get a generating function for the Fibonacci numbers.) The partial fraction decomposition of the RHS then determines a closed form for  in which the leading term is given by the pole of the RHS closest to the origin. General theorems assert, although we can prove directly, that this pole is positive, real, unique, and has multiplicity . So write
in which the leading term is given by the pole of the RHS closest to the origin. General theorems assert, although we can prove directly, that this pole is positive, real, unique, and has multiplicity . So write
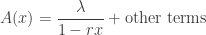
which implies that  . Here
. Here  is the largest positive root of the characteristic polynomial
is the largest positive root of the characteristic polynomial
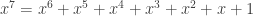
and since the two sides are approximately equal when 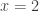 (and since we expect that, for small , is close to
(and since we expect that, for small , is close to  ) we conclude that should be a little less than . In fact, multiplying the above by
) we conclude that should be a little less than . In fact, multiplying the above by 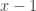 gives
gives
 .
.
The iteration 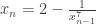 should converge rapidly to . In fact with
should converge rapidly to . In fact with  we get
we get  , and the difference between
, and the difference between  and
and  is negligible. So
is negligible. So  should be quite a good approximation.
should be quite a good approximation.
To estimate 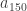 it now remains to estimate
it now remains to estimate  . We can compute directly in terms of using l’Hopital’s rule and the observation that is equal to
. We can compute directly in terms of using l’Hopital’s rule and the observation that is equal to  . We compute that this is equal to
. We compute that this is equal to
 .
.
This gives 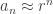 , so
, so
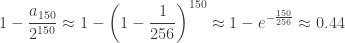 .
.
(If I estimated the error in my approximation of I might be compelled to give more digits, but this is fine for now.) So we see that, in agreement with the expected value calculation, the probability that at least one run of consecutive tails appears is quite good if the number of coins flipped is in the neighborhood of  (and the more general statement with replaced by another positive integer).
(and the more general statement with replaced by another positive integer).
The obvious generalization of the above computation shows that the probability that at least one run of  consecutive tails appears when coins are flipped are, if is not too small and is less than or around
consecutive tails appears when coins are flipped are, if is not too small and is less than or around  , reasonably close to
, reasonably close to 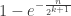 . If is significantly less than , the above is approximately
. If is significantly less than , the above is approximately  , which is within a factor of of the answer we would get if were significantly larger than and, in addition, we assumed that the events of the first coins, the next coins (again, coins through
, which is within a factor of of the answer we would get if were significantly larger than and, in addition, we assumed that the events of the first coins, the next coins (again, coins through 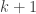 ), and so forth all turning up tails were independent (which they aren’t, but again, this is an approximation). If is significantly larger than then, of course, the probability approaches rather rapidly.
), and so forth all turning up tails were independent (which they aren’t, but again, this is an approximation). If is significantly larger than then, of course, the probability approaches rather rapidly.

I know this is quite old, but it can’t hurt to respond.
You can treat this as a markov chain, with transition matrix
[ p (1-p) 0 0 0 0 0 0; p 0 (1-p) 0 0 0 0 0; … ; p 0 0 0 0 0 0 (1-p); 0 0 0 0 0 0 0 1]
For the fair coin case, p = 0.5
Start with initial vector pi_0 = [p (1-p) 0 0 0 0 0 0] and iterate 149 times, either with matrix multiplication or perhaps diagonalization.
You get 0.441958742802… or so
Not as elegant, but direct. Probably much more accurate for small sizes.
A quick way of calcuting the asympotical result (generalizable to weighed coins):
Instead of throwing N coins, lets consider the experiment of throwing M alternate runs (a ‘run’ is a sequence of consecutive tails/heads). That is, instead of throwing N iid Bernoulli random variables, we throw M iid geometric random variables.
If we choose M=N/2, the expected total number of coins will be N, and so we can expect (informally) that the two experiments are asymtotically equivalent (in one experiment the number of coins is fixed, the number of runs is a random variable; in the other, the reverse; this could be related to the use of different ensembles in statistical physics).
In the modified experiment it’s easy to compute the probability that no run exceeds a length L: it’s just (1-(1/2)^(L-1))^(N/2)
If we consider just tails, the number of trials would be N/4 instead. This, in our case, gives 1-0.44160.
I had looked at this problem a while ago, and ended rediscovering the generalized Fibonacci numbers http://mathworld.wolfram.com/Fibonaccin-StepNumber.html
And I got (rather informally) the asymptotical result:
k = log_2(n) – G(p) + o(1) with
G(p) = 1 + log_2( – ln(1-p) )
It agrees with your last paragrpah, if I’m not mistaken.
Linearity of expectation of the number of patterns of exactly seven tails didn’t seem like the right tool to use because the probabilities of getting these patterns are so highly non-independent (if you get one, you have a much higher probability of getting a second one).
Instead, I used the following reasoning: each sequence of zero or more tails is started by a head, and you should have about 75 heads. The last three or so heads are likely too near the end to count, but otherwise each head has probability 1/128 of being followed by seven or more tails. So the expected number of consecutive sequences of seven OR MORE tails should be around 72/128, and I rounded that down to 1/2 to give my guess at the probability of at least one such sequence.
Fair enough. I was going to mention that the expected value computation was something of a copout for precisely the reason you describe, but it was just an easy computation for motivating the hard computation.